


In every organization that maintains one or more name-centric processes (NCPs), certain organizational resources (human and technical) are allocated to conduct and/or manage those processes. Improving the outcomes from processes such as name-screening, name-capture, match-merge/customer data integration in many instances can often require little more than doing a better job of matching existing organizational resources with various aspects of these NCPs. This can be the case whether the NCPs are internal assets, or are provided by sources external to the organization.
As an example, consider a typical Customer Identification Program (CIP) process in a hypothetical U.S. financial institution, as shown below.
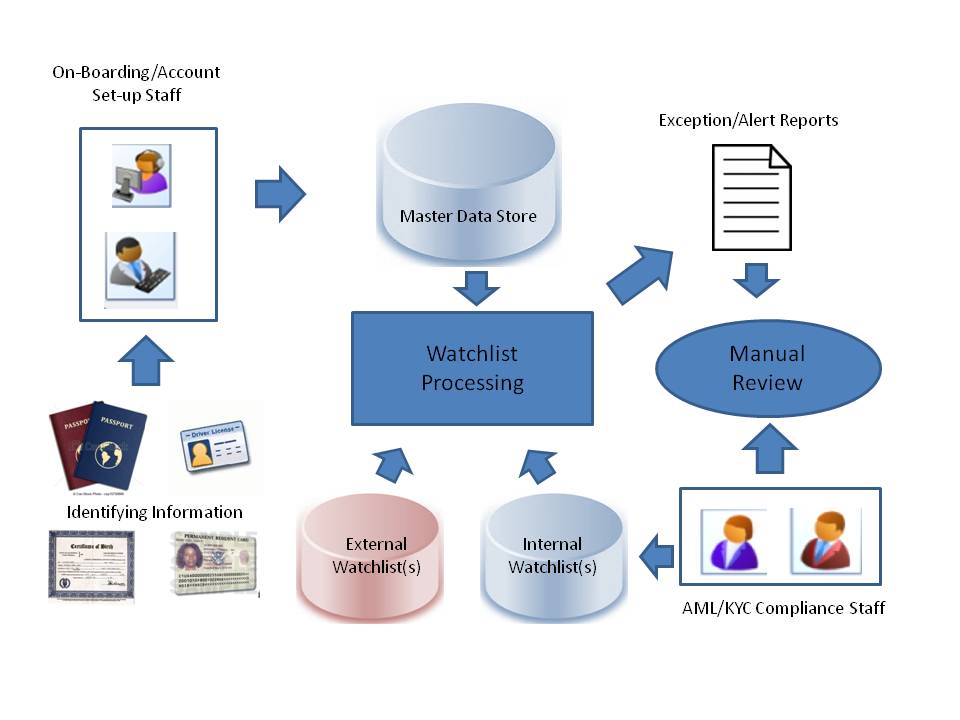
AML/KYC Processing Flow
In this example, names associated with newly opened accounts are collected from identification documents, added to a master data store, then vetted against both internal and external watch-list datasets by automated processes. There are at least three critical points where human judgment is often required: first, when the customer or business name is first collected from accepted identifying information, such as a passport, a driver’s license or a birth certificate; second, when the as-collected/as-verified name is screened against one or more name-lists; third, when a report is generated by the AML/KYC screening process, indicating a potential match between the account owner and one or more entries on an AML watch-list, whether internal or external in its provenance.
This processing sequence may be entirely within the control of a single component, and assigned staff may span all processing steps. However, it can be shown that each of the three steps in the sequence requires somewhat different skills, and thus might arguably be improved by personnel assignments that key on these particular skills.
Effective name-data capture is the logical first step in the processing flow. Extracting a name from multiple, sometimes inconsistent identification documents (all of which may be accepted as official) can be especially challenging, especially when this is done without a basic understanding of the particular ways names from unfamiliar languages and writing systems may be rendered in these documents. For example, many official documents (including those issued by the U.S. government) have both a human-readable and a machine-readable rendition of the bearer’s name, and the set of characters used to represent the name is not always the same in those two versions. Also, the machine-readable zone on many modern passports and visas has significant size-constraints (i.e., maximum number of characters), sometimes necessitating arbitrary truncations for certain names (e.g., Hispanic, Islamic). Knowing how to identify, collect and preserve the most complete and distinctive version of a personal or business name for effective, consistent CIP outcomes requires a variety of skills, all of which need to be identified, documented and cross-referenced within an organization’s HR assets, so that staff members tasked with collecting name and other identity data will either gain general competency on these points, or else they will know where expertise they need can quickly be obtained. It is especially important to define and document clear protocols regarding the relative priority of various identity documents, so that discrepancies between and among these can be resolved in a consistent way, when they occur.
The name-screening process, shown as logically subsequent to name-collection process, may be accomplished internal IT resources (“in-house’), or it may be provided as a service by an outside vendor (“outsourced”). The internal processing resources that are applied, in turn, may have been developed by IT staff or contractors managed by that staff, or they may be based on a commercial product. They key skills required in this phase are a solid general understanding of the data-flows and formats associated with the name-screening process, to ensure that each as-collected name does not undergo any unintended modifications (e.g., truncation, padding, re-parsing, concatenation) before it is vetted against the screening lists, since these may affect the accuracy of the matching logic in the name-screening process. Another key skill for this process is possession of a general overview of the organization’s name demographics, that is, knowing the predominant ethnic/linguistic/cultural types of the names that are being screened, understanding what special challenges these names may pose for the logic/algorithms of the matching process, and ensuring that these algorithms are adequate for such challenges.
At the far end of the AML/KYC processing flow, compliance analysts and other staff are typically tasked with reviewing each instance of an exception or alert that is generated from the AML screening system. In these instances, candidate matches from one or more “watch-lists” are provided for a name within the organization’s master-data repository. The candidate matches are often accompanied by additional fields of personal-identity data (e.g., date of birth, country of origin, home address, …) that can assist the AML analyst in determining whether or not a matched name from the watch-list references the same individual seeking to do business with the financial institution.
Just as with the name-collection staff, it is important to understand and to document the key skills required to make accurate, consistent assessments of potential watch-list matches/alerts. At a minimum, there needs to be a well-defined set of criteria applied to name-matches, so that it is well-understood when matched names are sufficiently similar to warrant further investigation, and when they are sufficiently different to be dismissed as “false positives”, which is the statistically predominant outcome in most settings.
Many organizations, especially larger ones, will prove to have a culturally and linguistically diverse set of HR assets. Far fewer have a clear idea which culture and language skills are most important for the decisions and transactions that present the greatest risk, nor have they worked out the best way to identify and document the processing and decision points where these skills can be deployed to best effect. One of the easiest and most cost-effective ways to improve NCPs across the board is to document the kinds of knowledge and expertise that are required in order to get names right as they enter the master-data repository, and in order to screen them correctly against watch-lists. Although these skills may be vested entirely in one or more individuals, it is more probable that they will be found scattered piecemeal across the organization.
Collecting these skills and delivering them to best effect in a timely, consumable fashion can be both a challenge and an opportunity for any organization that understands the importance of continuous improvement across its name-centric processes.
