


There’s no substitute for knowing…
In previous posts, I’ve attempted to convey some sense of the linguistic and cultural diversity that personal names exhibit, especially when these names are converted from other writing systems and social contexts into the Roman (A-Z) alphabet and the naming system that predominates in the English-speaking world. This diversity has important, even crucial significance for AML/KYC professionals whose responsibilities include screening names against OFAC and other sanctions lists.
But there are other factors to be considered in assessing the suitability and effectiveness of a name-screening operation, beyond the sophistication of the search techniques and the knowledge of its users. These factors are visible only obliquely, if at all, in the data comprised within the system, because they inhere in the logical design or “data semantics” of the components where names are broken into pieces and the parts are assigned labels.
The Silent Violence of Bad Name-Models
Over three decades of working with names in automated systems, I have been fortunate to enjoy some modest successes in getting decision-makers to acknowledge and plan for the kinds of linguistic and cultural complexity that personal names inevitably display, especially when processed in significant numbers. But, oddly, I have had far less success in getting these same executives to see that many of the persistent problems in their name-screening systems were self-inflicted, originating in subtle but ill-considered logical designs for the data-entry screens and data-tables that were used to capture and store names, and sometimes in the processing logic that was used to map from one automated component to another in a processing sequence, as is typical in ETL processing.
When a name is ill-suited for a screen form or a database record, decisions are made, by a human or by an automated proxy, that rarely if ever can be undone. It’s pretty hard to fix a broken name, once it has been taken up into a huge automated IT system, separated from its bearer and its supporting identity credentials. I suspect that many people share my history of oft-repeated frustration from efforts to correct an inaccurate rendition of my name in various financial or commercial accounts, and that name is not exactly exotic in the Anglophone world.
The PanAm 103 Experiment
Many years ago, as an experiment, I set up a web-page that listed the name of one of the Libyan nationals then under suspicion for the PanAm 103 bombing, Abdel Baset Muhammad Ali Al Megrahi (in Arabic: عبد الباسط محمد علي المقرحي). This web-page also had a data-entry form containing the familiar fields provided for capture of personal names in many systems, then as now: First, Middle and Last. The task on the web-page was simply to enter the name into the form. Within the first 40 responses, there were 14 different parses.
I then modified the data-entry form to provide the other typical and familiar name-entry fields: First and Last. The first two-dozen responses had six different interpretations. In both versions, some responses simply omitted the “left-over” pieces when all fields had been filled.
Because many automated name-screening systems depend on a consistent mapping of name-parts to data-elements, it’s easy to see why imposing Anglocentric name-models such as First-Middle-Last or First-Last can result in recurring “semantic violence” when names originating in very different name-models are forced to fit. And once that Submit button has been punched, the damage is pretty much done.
What is the OFAC name model?
One might look to OFAC for guidance as to the most appropriate name-model. The SDN list presents all names — Individuals, Organizations, Vessels, and more — in a single field, labelled as “SDN_Name.” Individual names are generally presented as having two comma-separated parts, one of which is present in all caps, and the other in title case.
I have not been able to discover any place on the OFAC website where the components of this “covert” name model are identified and labeled, but it sure looks like the standard Anglo-style Last,First model, stored entirely in a single field/data-element. I’m guessing that the implicit OFAC name-representation format would not be especially useful for most applications that store customer data. And that’s a shame, because a little leadership from OFAC would go a long way in establishing a best-practices paradigm that well-meaning AML/KYC operations could emulate beneficially. I have seen a fair number of organizations whose name-data is routinely damaged by using the First-Middle-Last name-model that seems so comfortable for familiar Anglo/Western European names, but proves to be a disastrously bad fit for the rest of the world.
Was Procrustes on your developer team?

Procrustes was a figure in Greek myth who lived beside a major trade route and lured in travelers for over-night stays with the promise of a luxurious bed that would fit anyone who slept in it. Turns out, he accomplished this feat simply by lopping off any limbs that exceeded the bed’s modest dimensions. That’s what’s going on in the figures shown on the Greek pottery at the left: some unlucky fellow is about to lose a leg. Apparently, Procrustes was not particularly concerned about his reviews on TripAdvisor…
If there are Procrustean features within your AML/KYC automation systems, the effects may be a little harder to identify than a severed limb, but the consequences for accuracy and consistency in the name-screening process may in fact be equally disastrous. What are the symptoms of name-lopping caused by poorly-fitted name-models and/or data designs, and what can be done to find and remedy the systematic degradation of name-data within complex IT architectures?
First, you’ll need to get all the names into a single repository, even temporarily, so that you can see the big picture
Next, scan the names to look for evidence of the following phenomena:
- Truncations, always at the same field-size (i.e., length in characters) in the name.
- Concatenations, where white-space was squeezed out in order to fit in more characters. These may occur between prefixes and stems (DE LA FUENTE~DELAFUENTE), or between consecutive name-stems (DAVID STEVEN~ DAVIDSTEVEN).
- Excessive occurrence of initals to represent one or more given-names, or initials that appear after the fur.
- Preponderance of single surnames used in Hispanic names, versus the more typical compound surnames, especially for married females.
- Seemingly anomalous and/or unfamiliar names that are not easily associated with any particular cultural or linguistic context. This is an admittedly impressionistic distinction, but even monolingual/monocultural Anglophones have been exposed to a reasonable number of names from a variety of ethnic sources, and thus have a reasonable (if not infallible) instinct for anomalous or damaged, versus unfamiliar, personal names (GONZAL~DJUGASHVILI)
Next, check the specifications for screens principally used for name-data capture, to see if there are edits applied for maximum acceptable length in one or more of the fields, then check to see how often data entered in those fields has attained the maximum length.
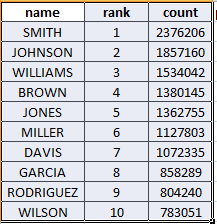
As possible extension of the name-data analysis, you could consider a simple little experiment in KYD analytics. This would involve tokenizing and inverting all the names in the aggregated repository, i.e., breaking them into their constituent pieces, then building a list of the unique items (tokens) you find, counting the frequency with which each token appears in your list. The name-tokens that occur very infrequently (once or twice) will be the most numerous in your inverted list, but that’s also where you’re most likely to find significant evidence of names found elsewhere in the list that have been put on the bed of Procrustes at some point, especially those “singletons” that also happen to be apparent sub-strings of other names on the list (e.g., JOHNSO~JOHNSON).
Once convincing evidence of chronic truncation is in hand, you can go to the IT specialists who are capable of tracing the damaged name-data back through the enterprise to the processing steps where you can find Procrustes at work.
Why Worry?
This almost certainly looks like quite a bit of work for potentially very little benefit, but I know of no surer or simpler way to find and eliminate the points at which bad things happen to good names, thereby diminishing greatly or eliminating entirely their value within the enterprise.
When every name comprised within an organization is put in a single pile, fresh insights and analytical angles become available, even with the most basic of tools. Essentially, this is the principle of “big data,” being applied to names. And why is that kind of insight made possible? Well, as one early-adopter of large-scale data analytics (whose surname actually was Djugashvili, BTW) put it best: “Quantity has a quality all its own.”
